2021 | 07
七月,在火上舞蹈。
前言
时间总是过得很快,一眨眼,半年时间没了。
7.1
起床时间:7:32
首先纪念今日,建党100周年,我很自豪生在中国,长在中国。
今天是星期四,熟悉的组会日,久违。
我很认真研习了本篇论文,仍是在组会上状况百出,我来记录一下问题。
M为什么是固定的?
切块进去吗?
后面会重新组合吗?
下采样?
固定shift吗?
仍需要去弄懂,并且写在论文review里。
共勉。
7.2
今天是星期五,我要去看《1921》,感谢彤子。
CV岗位面试题:encode和decode思想的差距在什么地方。
7.3
今天是周六,快乐的一天,按理说。
但是今天见到蟑螂了,但是今天也打死它了。
打死蟑螂后的慌张感迫使一个成年人喝一些液体来缓解,这种环节使我得到了暂时的缓解。
只是彼时的我并未意识到第二天的痛苦。
7.4
难受的我躺了一天,果然没有愧对周日这仨字。
感谢彤给我的俩锅贴,甚是感动。
我想去看《困在时光里的父亲》。
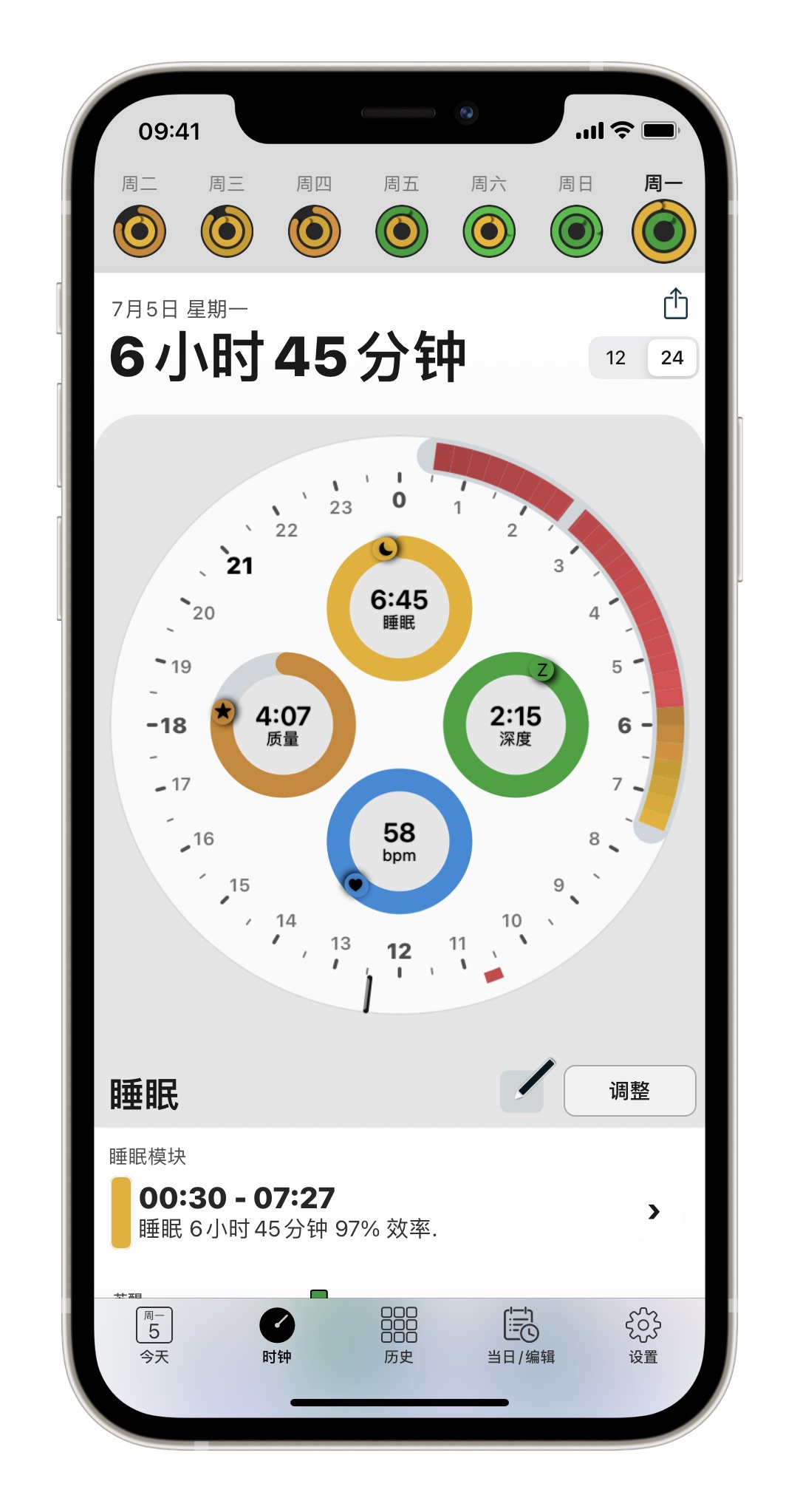
7.5
起床时间:7:39
今天是周一,我想我已经开始适应睡觉中途的醒来,看看时间,算算还能睡多久,然后继续睡觉,也索性自己的深度睡眠也达到了。
为什么我的AirPods连不上电脑(Macbook Pro)? - 知乎 (zhihu.com)
今日更新QQ音乐:

分词是词法分析(还包括词性标注和命名实体识别)中最基本的任务,可以说既简单又复杂。说简单是因为分词的算法研究已经很成熟了,大部分的准确率都可以达到95%以上,说复杂是因为剩下的5%很难有突破,主要因为三点:
- 粒度,不同应用对粒度的要求不一样,比如“苹果手机”可以是一个词也可以是两个词
- 歧义,比如“下雨天留人天留我不留”
- 未登录词,比如“skrrr”、“打call”等新兴词语
详见 NLP分词算法深度综述
卷积核的通道应该和输入的通道一样,但卷积核的数量是输出的通道。
7.6
起床时间:7:39
由于手机内存一直爆炸,问题出在备忘录,那我就很纳闷,我的备忘录不断清理的情况下从37g到了43g…
也有可能只是显示问题,但绝对不可能让我手机爆炸这么多天还是显示问题,于是我搜索后发现可以全部上传到iCloud上后再删除备忘录,最后再移回来。

macOS上使用Openconnect代替Cisco Anyconnect
-
1 * 1卷积的主要作用有以下几点:
1、降维( dimension reductionality )。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1 * 1的卷积,那么结果的大小为500 * 500 * 20。
2、加入非线性。卷积层之后经过激励层,1 * 1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation),提升网络的表达能力;
-
看到一个很好的关于
baseline的解释:baseline 就只是**「参照物」**的意思,至于 baseline 系统是怎么来的、性能如何,并没有一定的标准。
比如:
如果你是机器学习的初学者,在做课程作业,那么你可能用「随机猜测」作为 baseline;
如果你是要在顶会发论文,那么很可能就需要用当前最好的系统(称为 state of the art)来作 baseline,否则审稿人就会质疑。
如果你的论文的论点是「我针对某系统作了改进,提升了性能」,那么 baseline 就应该是未改进的系统(相当于生物实验中的「对照组」),它与改进后的系统只有一处不同,这样才能下结论说你的改进就是提升性能的原因。如果你的论文的论点是「我提出的方法 A 比已有的方法 B 更好」,那么 baseline 就应该是方法 B,即使它跟方法 A 毫无关系。
当你选定了一个 baseline 系统后,如果你能联系上作者,索取到他的代码,就可以直接用作者的实现作为 baseline;如果联系不上,就只能自己复现。
有时候,你选择的 baseline 是你要研究的更广阔的框架下的一个特例,而你自己实现了框架下的其它方法,此时为了让系统之间只有一处不同,你可能会主动选择在框架下重新实现 baseline。
如果你是参加比赛,那么主办方常常会主动提供 baseline 系统。你可以在它的基础上做修改,也可以另起炉灶重新实现自己的系统。
参考:https://www.zhihu.com/question/313705075/answer/1600825423
-
rank1评测标准:
搜索结果中最靠前的一张图是正确结果的概率,一般通过实验多次来取平均值。
-
mixup
mixup是一种运用在计算机视觉中的对图像进行混类增强的算法,它可以将不同类之间的图像进行混合,从而扩充训练数据集。参考: 数据增强之mixup算法详解
7.7
起床时间:7:42
分享正确代码:
itertools.product()结构及用法_漫步量化-CSDN博客
7.8
起床时间:8:20
-
model.eval() 和 train() 区别
model.train() :启用 BatchNormalization 和 Dropout
model.eval() :不启用 BatchNormalization 和 Dropout
7.9
起床时间:8:20
今日终于弄完了大概pyTorch,感觉有些书真的很烂,示例代码也烂,没有注释,更烂了。
啊!
7.10
周六。
在痛苦中度过。
这种痛苦总和一种极致的快乐相连接。
7.11
周日。
7.12
起床时间:7:42
今天是周一。
-
what’s the token?
What is Tokenization | Tokenization In NLP (analyticsvidhya.com)
今天在看论文《CSWin Transformer》,只能佩服科研人员的能力,见到什么就立马有新的idea,cross- shaped是真的顶👍,而且在location embedding上做文章,牛。

7.13
起床时间:7:49
- 神奇且困倦的一天
7.14
起床时间:8:20
如果说今天,其实是神奇的一天。
要好好写一个需求报告。
加油吧!
7.15
起床时间:8:42
写完了OS的课设报告。
7.16
今天是周五,但是我并没有按时早起,也许是熬夜的原因。
7.17
回家家。
7.18
是出去吃饭饭的一天,饼饼。
7.19
是在家呆着的一天,是新疆炒米粉。
7.20
去吃了涮羊肉,不得不说,涮羊肉是热的,现在都渴渴的。
7.21
大家好,今天是7月21日,在河南暴雨后的第几天,我在家里得到许多询问,我觉得很多时候大家都是伟大的。
尤其是我在看到许多视频之后,心里更多的是敬畏,敬畏无数的平凡人,平凡人做的不平凡的事情。
7.22
我一定要花一天把我的一周总结写到现在!
还有我要写一下需求报告了!!
7.23
其实我很多时候都不太清楚每天做了什么,因为混乱。
7.24
祝福杨倩,祝福侯志慧。
今天看中国女足,还是可惜没有李影。
之前的期望是战平荷兰,打赢赞比亚才有希望,但今天在3:1的领先下还是被超越,幸好王霜的点球扳平了局面。
下一场怎么办呢,还靠王霜?
7.25
我倒是应该做些正事,这是社会赋予我的正能量。
7.26
7.27
7.28
7.29
7.30
7.31
愉快的最后一日是女排3:0。
最近疫情越来越严重,令人有些难过。
所以什么时候疫情会过去呢?